Multi-Metric Preference Alignment for Generative Speech Restoration
Abstract
Recent generative models have significantly advanced speech restoration tasks, yet their training objectives often misalign with human perceptual preferences, resulting in suboptimal quality. While post-training alignment has proven effective in other generative domains like text and image generation, its application to generative speech restoration remains largely under-explored. This work investigates the challenges of applying preference-based post-training to this task, focusing on how to define a robust preference signal and curate high-quality data to avoid reward hacking. To address these challenges, we propose a multi-metric preference alignment strategy. We construct a new dataset, GenSR-Pref, comprising 80K preference pairs, where each chosen sample is unanimously favored by a complementary suite of metrics covering perceptual quality, signal fidelity, content consistency, and timbre preservation. This principled approach ensures a holistic preference signal. Applying Direct Preference Optimization (DPO) with our dataset, we observe consistent and significant performance gains across three diverse generative paradigms: autoregressive models (AR), masked generative models (MGM), and flow-matching models (FM) on various restoration benchmarks, in both objective and subjective evaluations. Ablation studies confirm the superiority of our multi-metric strategy over single-metric approaches in mitigating reward hacking. Furthermore, we demonstrate that our aligned models can serve as powerful ''data annotators'', generating high-quality pseudo-labels to serve as a supervision signal for traditional discriminative models in data-scarce scenarios like singing voice restoration.
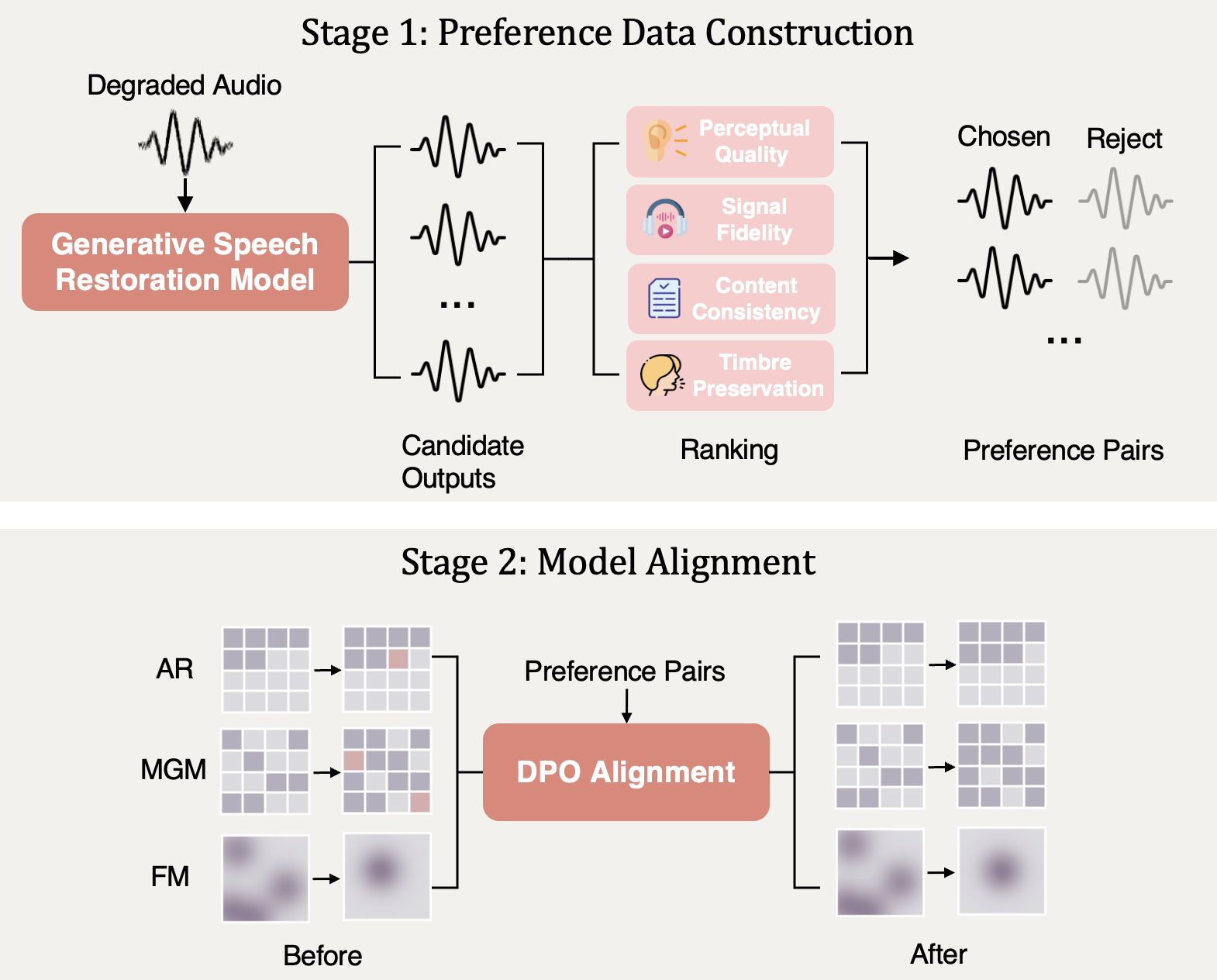
Our approach to aligning generative speech restoration models is centered around a multi-metric preference alignment strategy, which is illustrated above. This strategy involves two key stages: first, the construction of a high-quality preference dataset, and second, the application of Direct Preference Optimization (DPO) to align the model with these preferences. This approach is designed to be model-agnostic, allowing it to be applied to any generative restoration model.
Demo Audio
Autoregressive(AR)
AR models generate clean speech token by token in sequence, optimizing cross-entropy loss over the ground-truth sequence.

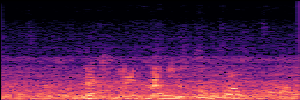
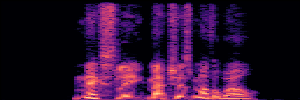
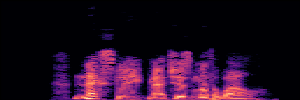
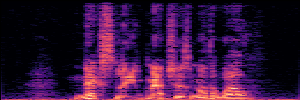
Masked Generative Model(MGM)
MGM models restore clean speech from partially masked inputs by predicting original tokens, using a masked language modeling objective.
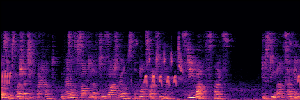
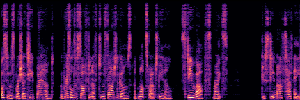
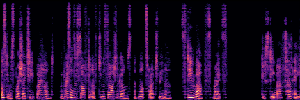
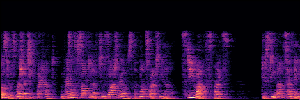
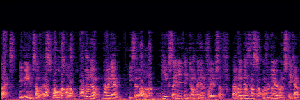
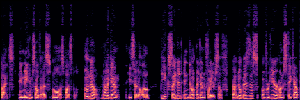
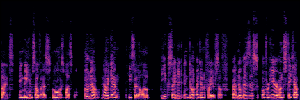
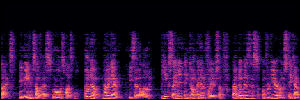



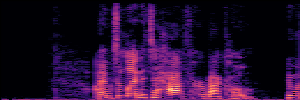
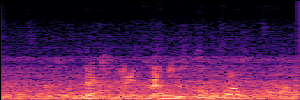
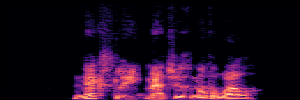
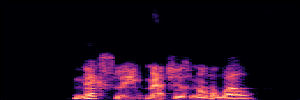

Flow Matching(FM)
FM models learn a velocity field that maps noise to clean speech along a continuous path, minimizing the difference between predicted and true flow directions.
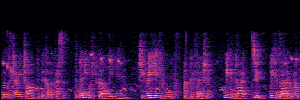
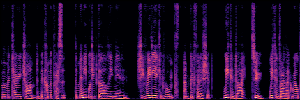
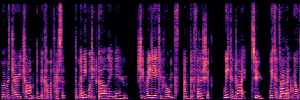
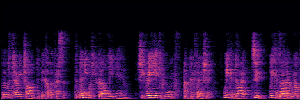
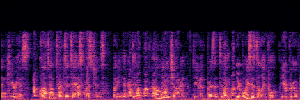
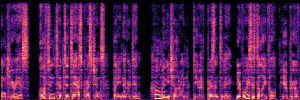
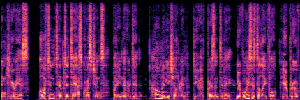
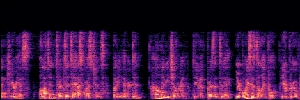
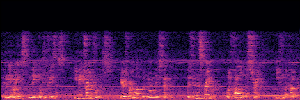


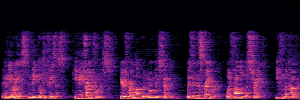
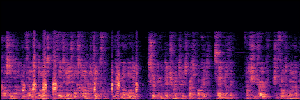
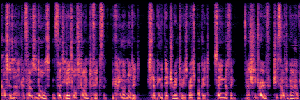
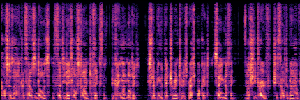
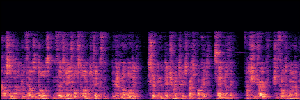
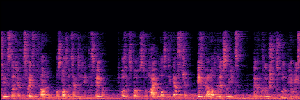
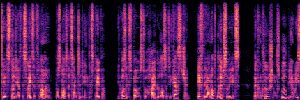
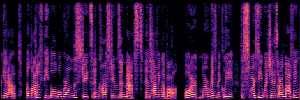
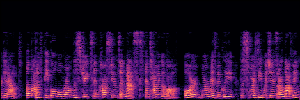
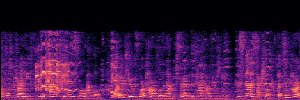
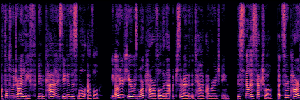
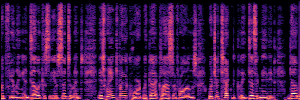
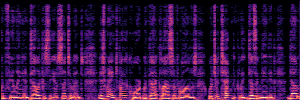
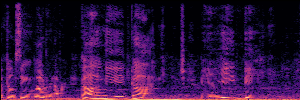
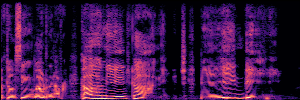
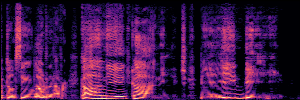
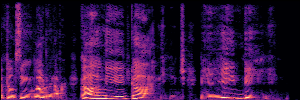
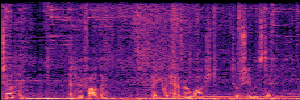
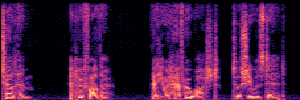
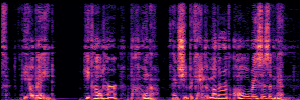
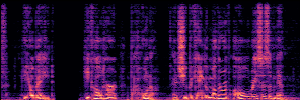
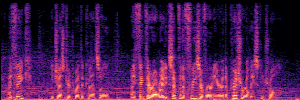
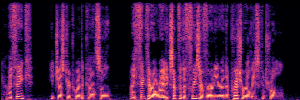
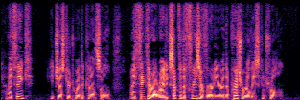
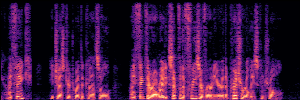
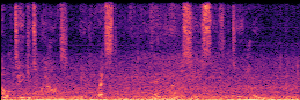
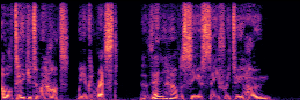

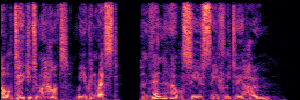
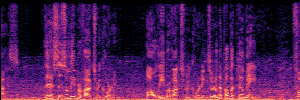
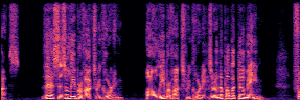
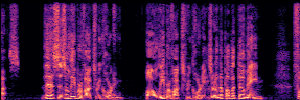
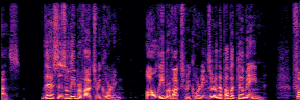
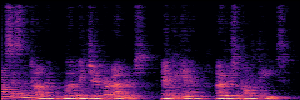
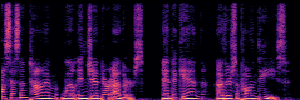
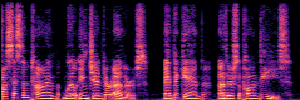
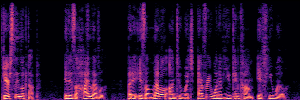
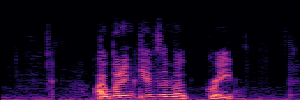
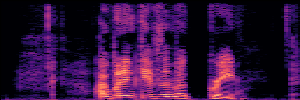
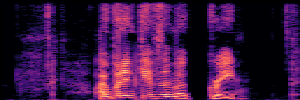
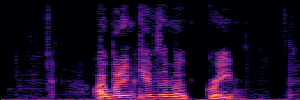

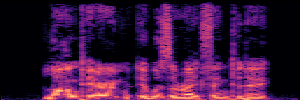
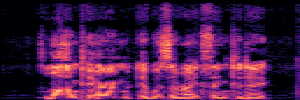
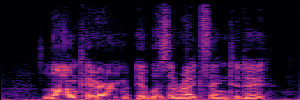
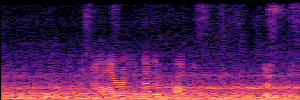
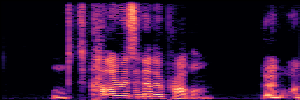
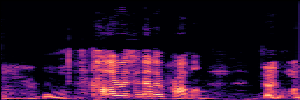
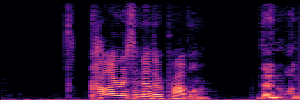
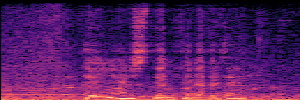
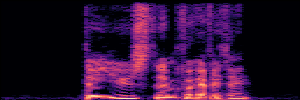
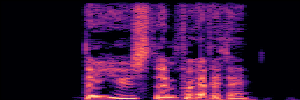
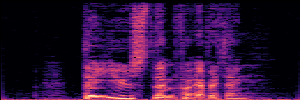
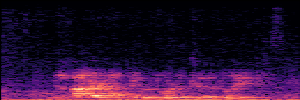
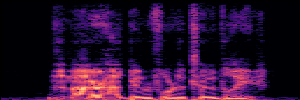
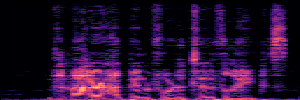
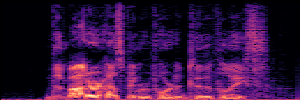
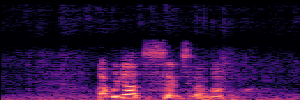
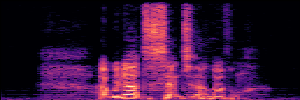
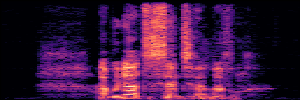
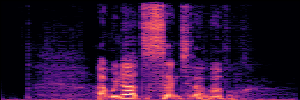

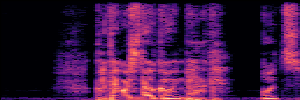
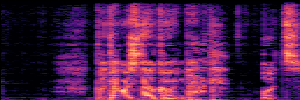
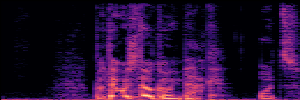
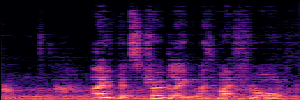
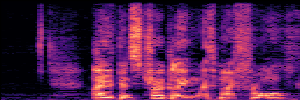
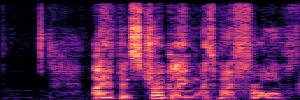
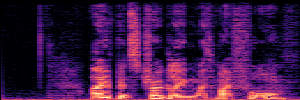
Application: Empowering Discriminative Models via Pseudo-Labeling
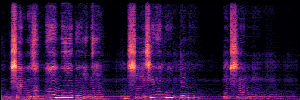
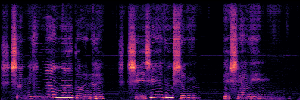
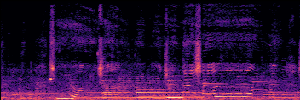
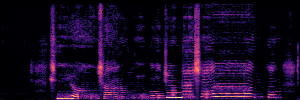
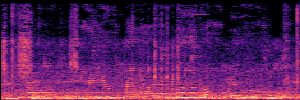
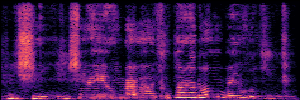
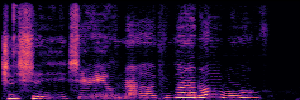
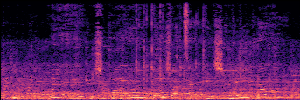
To showcase the practical utility of our aligned models, we explore their potential as ''data annotators'' in a scenario where ground-truth is scarce: real-world singing voice restoration. We took a standard discriminative restoration model, Voicefixer, and fine-tuned it on a set of singing recordings. The key difference is that the ''clean'' supervision signals were not ground-truth recordings, but pseudo-labels generated by our DPO-enhanced AnyEnhance model.| Raw Recording (Noisy) | Initial Voicefixer Output | Output After Pseudo-Label Fine-Tuning |
|---|---|---|
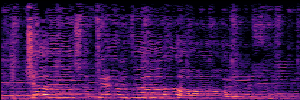 |
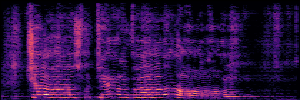 |
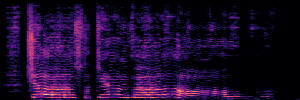 |
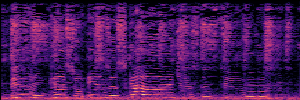 |
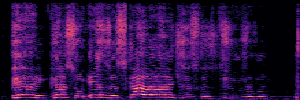 |
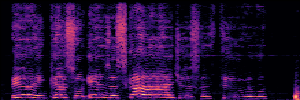 |
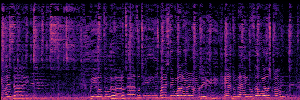 |
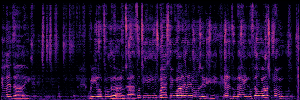 |
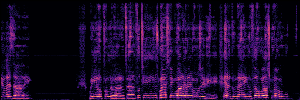 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |